DEVMODE Community adalah platform kreator, tech founder dan developer untuk belajar, berdiskusi, dan berkarya di dunia digital.
Dipublikasikan 29 Mei 2026
Liquid AI Rilis LFM2.5-8B-A1B: Model MoE On-Device yang Lebih Cepat
Liquid AI baru-baru ini merilis LFM2.5-8B-A1B, model Mixture-of-Experts (MoE) yang dirancang untuk tool calling cepat dan andal pada hardware konsumen. Menurut pengumuman resmi di blog Liquid AI, model ini membangun fondasi dari LFM2-8B-A1B yang dirilis Oktober 2025, dengan peningkatan signifikan di beberapa aspek kunci.
Peningkatan paling mencolok adalah perluasan context window dari 32.768 ke 128.000 token, yang memungkinkan model memproses dokumen lebih panjang dan melakukan reasoning yang lebih mendalam. Training data juga ditingkatkan dari 12 triliun menjadi 38 triliun token, disertai reinforcement learning berskala besar. Liquid AI juga menggandakan ukuran vocabulary dari 65.536 menjadi 128.000 untuk meningkatkan efisiensi tokenisasi bahasa non-Latin, termasuk Indonesia, Thai, Hindi, Vietnam, dan Arab.
Model Reasoning-Only untuk Edge
Berbeda dengan pendahulunya, LFM2.5-8B-A1B adalah reasoning-only model yang menghasilkan chain of thought eksplisit sebelum jawaban akhir. Liquid AI memilih strategi ini karena model MoE umumnya beroperasi dalam setting compute-bound, di mana jumlah parameter aktif yang lebih kecil membuat setiap token reasoning menjadi murah. Pendekatan ini memberikan quality boost signifikan tanpa mengorbankan kecepatan.
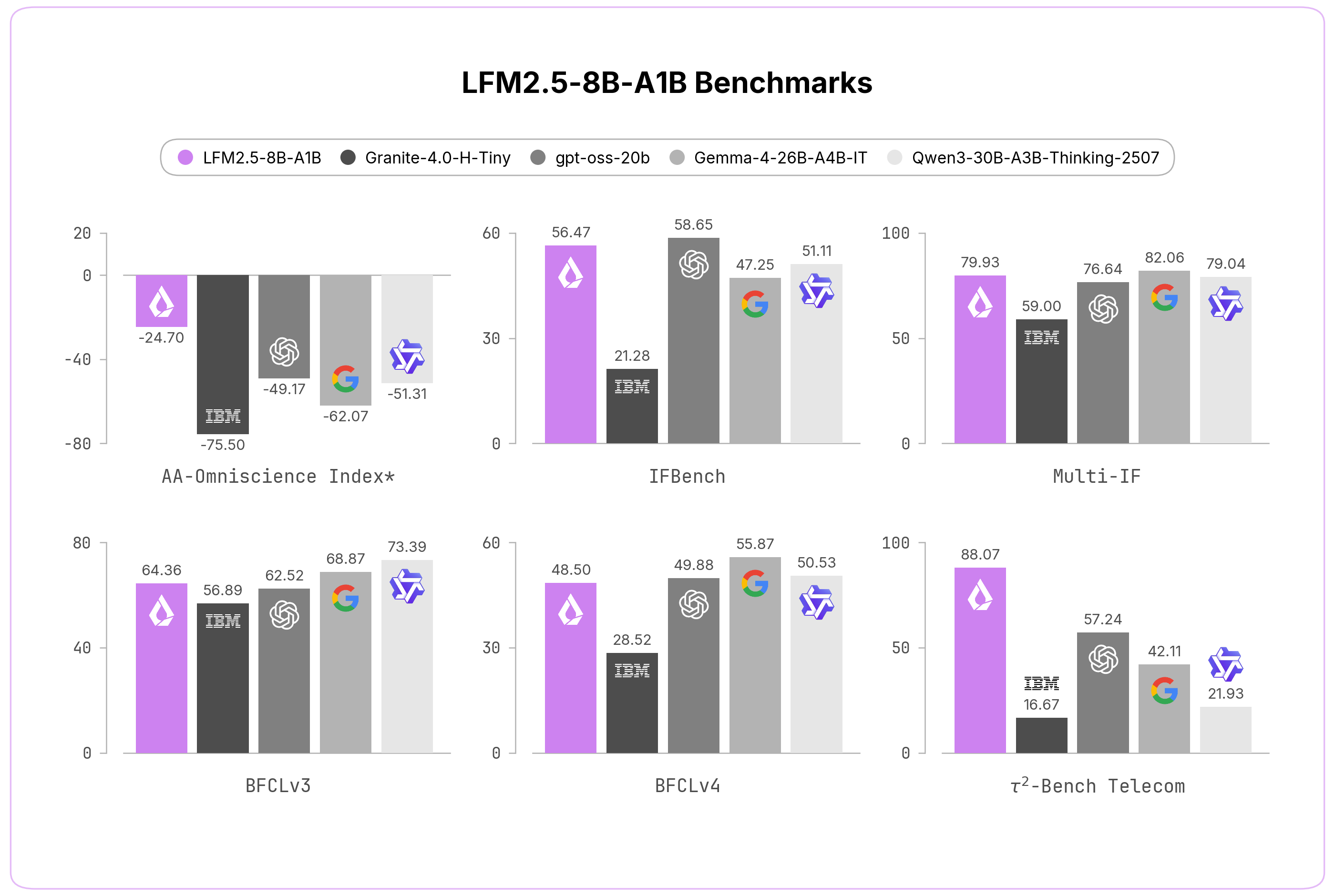
Hasilnya terlihat jelas di benchmark. Pada AA-Omniscience Non-Hallucination Rate, model ini melonjak dari 7,46% (versi lama) menjadi 63,47% - peningkatan lebih dari 56 poin persen. Pada benchmark agentic Tau2-Telecom, skor naik dari 13,60% menjadi 88,07%. Peningkatan dramatis ini menunjukkan bahwa edge model kecil dengan arsitektur yang tepat bisa sangat kompetitif.
Performa Inference yang Memimpin
LFM2.5-8B-A1B diklaim sebagai model tercepat di kelasnya pada inference CPU dan GPU. Pada CPU, model ini mencapai 253 token/detik pada Apple M5 Max dan 146 token/detik pada Ryzen AI Max+ 395 dengan konsumsi memori di bawah 6 GB. Bahkan pada ponsel, model ini tetap bertahan di sekitar 30 token/detik. Pada GPU NVIDIA H100 menggunakan SGLang, model ini mencapai 18.500 output token/detik pada high concurrency.
Model ini hadir dengan dukungan day-one di seluruh ekosistem inference: LEAP (platform edge AI Liquid), llama.cpp, MLX untuk Apple Silicon, vLLM, SGLang, dan ONNX. Versi base dan post-trained tersedia di Hugging Face tanpa restricsi.
LocalCowork: Agent On-Device
Untuk menunjukkan kemampuan praktisnya, Liquid AI memperbarui demo open-source LocalCowork untuk berjalan pada LFM2.5-8B-A1B. Setup yang sama seperti demo LFM2-24B-A2B sebelumnya: satu laptop, 67 tools di 13 MCP server, tanpa cloud, tanpa API key, tanpa data keluar dari mesin. Loop tool-dispatch terasa interaktif dengan latensi di bawah satu detik per dispatch.
Liquid AI juga melakukan inovasi pada tokenizer. Dengan memperluas vocabulary secara in-place dari tokenizer existing dan melanjutkan BPE merge training pada corpus multilingual, mereka berhasil meningkatkan efisiensi tokenisasi bahasa Indonesia sebesar 28,6% dan bahasa Thailand hingga 238%. Ini berarti teks non-Latin bisa diproses dengan lebih ringkas dan efisien.
Dengan LFM2.5, Liquid AI mempertegas visinya: AI yang berjalan di mana saja, dengan open-weight, dukungan lintas-platform dari hari pertama, dan performa yang kompetitif dengan model yang jauh lebih besar. Masa depan agentik on-device dimulai di sini.

Punya Produk Keren? Showcase Sekarang!
Dapatkan feedback, users, dan eksposur dari komunitas kreator, developer, dan entrepreneur digital Indonesia.
Submit Produk → Pelajari Dulu