DEVMODE Community adalah platform kreator, tech founder dan developer untuk belajar, berdiskusi, dan berkarya di dunia digital.
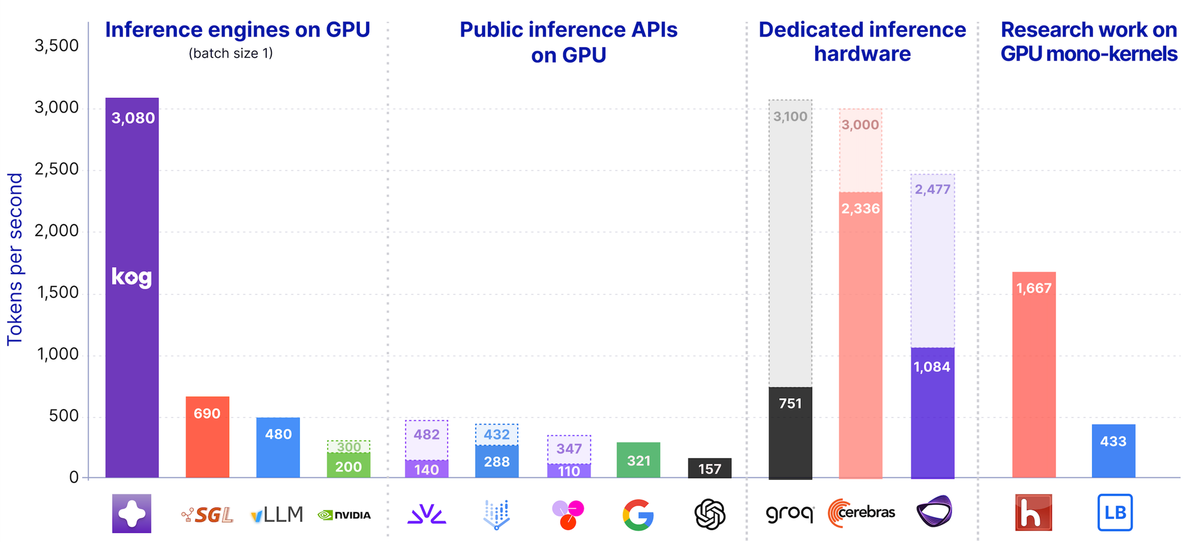
Startup AI asal Paris, Kog AI, baru-baru ini meluncurkan tech preview dari Kog Inference Engine (KIE) yang mengklaim mampu menghasilkan 3.000 output token per detik per request pada konfigurasi 8x AMD MI300X GPU, dan 2.100 token/detik pada 8x NVIDIA H200. Yang menarik, pencapaian ini diraih pada model 2B parameter dengan presisi FP16, tanpa mengandalkan teknik speculative decoding sama sekali. Menurut laporan dari blog resmi Kog AI, langkah ini menantang anggapan bahwa inferensi LLM real-time hanya mungkin di hardware inferensi khusus.
Inferensi single-request yang super cepat ini menjadi semakin krusial seiring munculnya AI agents yang menjalankan loop sekuensial: inspeksi, perencanaan, pengeditan, pengujian, dan revisi. Setiap langkah bergantung pada langkah sebelumnya. Jika sebuah agen perlu menghasilkan 50.000 token dalam satu alur kerja, kecepatan 100 token/detik berarti waktu tunggu sekitar delapan menit. Dengan 3.000 token/detik, waktu tersebut menyusut menjadi di bawah 20 detik - sebuah perbedaan yang mengubah produk yang bisa dibangun.
Mengapa Memory Bandwidth adalah Kunci
Pada batch size 1, decoding autoregresif didominasi oleh pekerjaan matrix-vector. Setiap token yang dihasilkan mengharuskan seluruh bobot model aktif dipindahkan melalui hierarki memori GPU, dari HBM ke prosesor komputasi. Inilah mengapa Memory Bandwidth Utilization (MBU) menjadi metrik sentral untuk kecepatan single-request, bukan Model FLOP Utilization (MFU).
Sebuah node 8x NVIDIA H200 secara teoritis menawarkan sekitar 30,7 TB/s aggregate memory bandwidth. Untuk model 2B parameter di FP16 (sekitar 4 GB bobot aktif), batas teoretis kecepatan bisa mencapai ~7.700 token/detik. Namun, software bottleneck pada stack inferensi konvensional membuat sebagian besar bandwidth ini terbuang percuma.
Monokernel dan Co-Design
Kog AI mengidentifikasi bahwa stack inferensi standar - seperti PyTorch, Triton, vLLM, atau TensorRT-LLM - memiliki overhead mikrodetik di setiap lapisan: kernel launch, sinkronisasi grid, komunikasi inter-GPU, sampling di CPU, dan lainnya. Pada target 3.000 token/detik, anggaran waktu per token hanya sekitar 333 mikrodetik. Overhead kecil di setiap lapisan dengan cepat menumpuk dan membatasi kecepatan pada ~890-1.780 token/detik.
Solusinya adalah monokernel: satu program GPU yang persisten untuk seluruh jalur decode, menghilangkan batasan antar-kernel dan scheduling dari CPU. Ditambah dengan KCCL (komunikasi kolektif kustom) dan arsitektur Laneformer dengan Delayed Tensor Parallelism, Kog mengko-desain model, runtime, dan kode GPU tingkat rendah sebagai satu sistem terintegrasi.
Preview publik ini menunjukkan bahwa GPU datacenter standar yang sudah dimiliki enterprise bisa mencapai kecepatan yang sebelumnya hanya mungkin di silicon proprietary. Kog menyediakan playground live untuk menguji kecepatan tersebut. Startup yang didirikan oleh Gael Delalleau ini telah mengumpulkan 5M USD dan diakui sebagai French Tech 2030.

Punya Produk Keren? Showcase Sekarang!
Dapatkan feedback, users, dan eksposur dari komunitas kreator, developer, dan entrepreneur digital Indonesia.
Submit Produk → Pelajari Dulu