DEVMODE Community adalah platform kreator, tech founder dan developer untuk belajar, berdiskusi, dan berkarya di dunia digital.
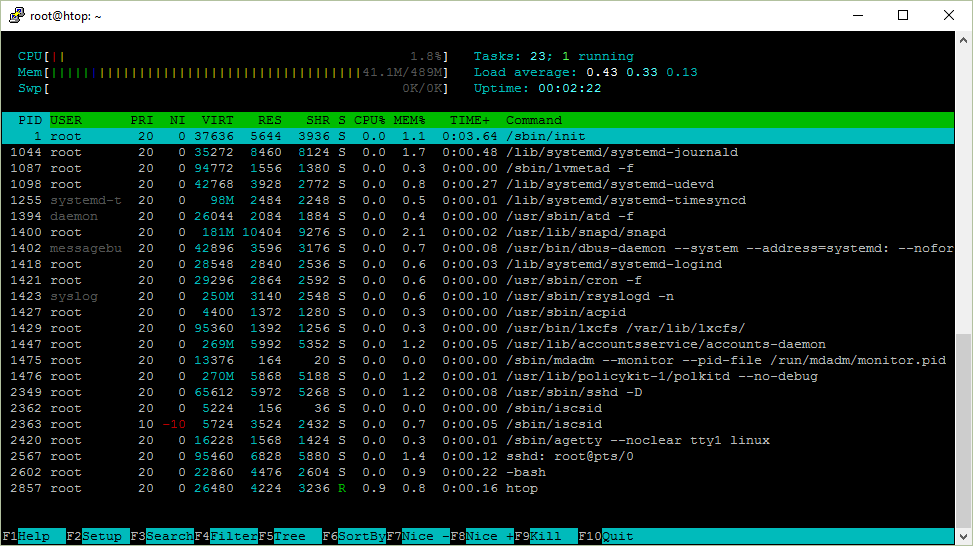

Sebagai developer yang sering deploy aplikasi ke server Linux, saya dulu sering bingung saat membuka htop. Angka-angka di layar terlihat teknis dan tidak intuitif. Load average 1.0 di mesin dual core artinya CPU usage 50% atau justru overload? Kolom VIRT, RES, SHR itu bedanya apa? Artikel ini adalah panduan praktis untuk membaca htop dan top dengan benar, berdasarkan penjelasan detail dari Peteris Rocks yang telah membantu ribuan developer memahami tool monitoring ini.
Mengenal Interface htop
Ketika kamu menjalankan htop di terminal, layar akan menampilkan baris-baris informasi sistem secara real-time. Bagian atas menunjukkan uptime, load average, dan grafik penggunaan CPU serta memory. Bagian bawah adalah daftar proses yang sedang berjalan beserta detail resource yang dikonsumsi masing-masing. Keunggulan htop dibanding top adalah tampilannya yang interaktif dan berwarna, sehingga lebih mudah dibaca saat troubleshooting dilakukan dalam tekanan.
Langkah 1: Memahami Uptime dan Load Average
Baris pertama di bagian atas menampilkan uptime, contohnya up 111 days, 31 min. Informasi ini diambil dari file /proc/uptime yang ada di setiap sistem Linux. Angka pertama di file tersebut adalah total detik sistem telah berjalan, sedangkan angka kedua adalah waktu idle. Waktu idle bisa lebih besar dari uptime total jika sistem punya multiple core, karena angka tersebut merupakan jumlah idle time dari semua core.
Tiga angka load average di sebelah uptime merepresentasikan rata-rata beban sistem dalam 1, 5, dan 15 menit terakhir. Banyak yang salah kaprah menganggap load average adalah persentase penggunaan CPU. Padahal load average dihitung dari jumlah proses yang sedang running atau waiting untuk berjalan, ditambah proses dalam uninterruptible sleep yang biasanya sedang menunggu I/O. Jadi load average 1.0 di mesin single core berarti CPU fully utilized. Di mesin dual core, load average 1.0 berarti utilization baru 50%, karena masih ada satu core yang bisa menerima proses. Jika load average lebih besar dari jumlah core, artinya ada proses yang mengantri di run queue.
Langkah 2: Membaca Kolom Process ID dan User
Setiap proses di Linux memiliki PID (Process ID) unik yang di-assign oleh kernel saat proses dibuat. PID 1 selalu dimiliki oleh /sbin/init atau systemd, yang merupakan proses pertama yang dijalankan saat boot. Kolom USER menunjukkan pemilik proses. Jika kamu melihat proses yang berjalan sebagai root tapi seharusnya tidak, itu bisa jadi indikator adanya anomaly atau bahkan security breach. Dalam kontainerisasi dengan Docker, USER juga penting untuk memastikan proses tidak berjalan sebagai root secara tidak perlu.
Langkah 3: Memahami Process State
Kolom S menunjukkan state proses. Berikut daftar state yang paling sering muncul dan artinya:
R (Running/Runnable): Proses sedang berjalan atau menunggu giliran di CPU run queue. Ini adalah state aktif yang mengonsumsi resource.
S (Interruptible Sleep): Proses menunggu event selesai, contohnya menunggu input dari user, response dari network, atau data dari disk. Proses dalam state ini bisa di-interupsi oleh sinyal.
D (Uninterruptible Sleep): Biasanya proses sedang menunggu I/O disk. State ini tidak bisa diinterupsi, bahkan oleh sinyal SIGKILL. Jika terlalu banyak proses dalam state D, biasanya ada masalah dengan storage subsystem atau filesystem yang hang.
Z (Zombie): Proses telah terminated tapi parent belum memanggil
wait()untuk membaca exit status-nya. Zombie tidak mengonsumsi resource, tapi jika jumlahnya bertambah terus bisa mengindikasikan bug di parent process.T (Stopped): Proses dihentikan oleh job control signal, misalnya dengan Ctrl+Z. Proses bisa di-resume dengan perintah
fgataubg.
Langkah 4: Memahami Penggunaan Memory
htop menampilkan empat kolom utama terkait memory yang sering membingungkan pemula:
VIRT/VSZ: Total virtual memory yang dialokasikan proses, termasuk yang belum benar-benar digunakan di RAM fisik. VIRT bisa mencakup memory yang di-swapped ke disk dan memory-mapped files. Angka ini biasanya lebih besar dari memory yang benar-benar dipakai.
RES/RSS: Resident Set Size, yaitu jumlah memory fisik (RAM) yang benar-benar digunakan proses saat ini. Ini adalah angka yang paling relevan untuk melihat seberapa besar memory footprint sebuah aplikasi.
SHR: Shared memory, biasanya digunakan oleh shared libraries yang dipakai beberapa proses sekaligus. SHR termasuk dalam RES, jadi jika kamu menjumlahkan RES semua proses, totalnya bisa lebih besar dari RAM fisik karena SHR dihitung berkali-kali.
MEM%: Persentase total RAM sistem yang digunakan oleh proses tersebut. Ini dihitung dari RES dibagi total RAM.
Untuk troubleshooting memory leak, fokuslah ke kolom RES. Jika RES terus meningkat tanpa turun meski traffic normal, itu red flag yang menandakan adanya leak. Kamu bisa menggunakan tool tambahan seperti valgrind atau memleak dari BCC untuk investigasi lebih lanjut.
Langkah 5: Memahami Niceness dan Priority
Kolom NI menunjukkan nice value, sedangkan PRI adalah priority yang dihitung oleh kernel. Nice value berkisar dari -20 (prioritas tertinggi) hingga 19 (prioritas terendah). Proses dengan nice value negatif akan mendapatkan lebih banyak waktu CPU. Secara default, proses yang kamu jalankan memiliki nice value 0. Kamu bisa mengubahnya dengan perintah nice -n 10 ./script.sh untuk menurunkan prioritas, atau sudo renice -n -5 -p 1234 untuk meningkatkan prioritas proses yang sedang berjalan. Namun hanya root yang bisa menaikkan nice value (membuat lebih negatif).
Langkah 6: Praktik Troubleshooting Langsung
Berikut workflow troubleshooting yang saya pakai saat server mengalami slowdown atau anomali resource usage:
Buka htop dan perhatikan load average di bagian atas. Jika angkanya lebih besar dari jumlah core CPU, artinya ada proses yang mengantri dan sistem kelebihan beban.
Sort proses by CPU% atau MEM% dengan menekan F6 dan memilih kriteria sort. Identifikasi proses yang paling boros resource.
Cek state proses di kolom S. Jika banyak proses berada di state D, kemungkinan bottleneck ada di disk I/O. Cek juga apakah ada zombie processes yang menumpuk.
Periksa USER dan COMMAND. Pastikan tidak ada proses suspicious yang berjalan, terutama proses yang tidak kamu kenali dengan user root.
Jika perlu, tekan F9 untuk mengirim sinyal ke proses bermasalah. Sinyal default adalah SIGTERM (15) yang meminta proses untuk terminasi gracefully. Jika proses tidak merespons, gunakan SIGKILL (9) yang memaksa terminasi.
Kesimpulan
htop bukan sekadar task manager cantik di terminal. Setiap angka dan kolom di dalamnya memberikan informasi berharga tentang kesehatan sistem. Dengan memahami load average, process state, memory breakdown, dan priority scheduling, kamu bisa mendiagnosis masalah server dengan lebih cepat dan tepat. Untuk developer yang sering bekerja dengan remote server atau VPS, keahlian membaca htop adalah soft skill teknis yang sangat bernilai.
Sumber referensi: htop explained oleh Peteris Rocks.

Punya Produk Keren? Showcase Sekarang!
Dapatkan feedback, users, dan eksposur dari komunitas kreator, developer, dan entrepreneur digital Indonesia.
Submit Produk → Pelajari Dulu